
Ядро операционной системы: что собой представляет и что входит в состав

Ядро операционной системы представляет собой центральную программную часть любой системы. То ест ь я дро присутствует у каждой ОС: Windows, Linux и др. Оно координирует доступ сторонних программ к жизненно важным ресурсам компьютера, например:
времени работы процессора;
внешним аппаратным устройствам, подключенным к компьютеру;
устройствам ввода и вывода информации;
Когда мы произносим слово «ядро», у большинства людей возникает ассоциация с чем-то круглым. Однако ядро операционной системы представляет собой основной программный код. Его можно представить, ассоциируя с ядром Земли. Каждый пользователь еще из курса школьной географии знает, что внутри Земли расположено ядро, а поверх ядра располагаются:
земная кора, на поверхности которой живут люди.
Ядро операционной системы компьютера работает по такой же схеме. Оно расположено «глубоко внутри», а поверх него нанизывают все остальное, чт о в комплекс е и составляет компьютерное устройство:
Ядро операционной системы
Ядро операционной системы — это некая программа. Каждая программа в программировании разрабатывается на основе определенной архитектуры, структуры, шаблона. Поэтому ядра могут быть представлены в нескольких архитектурах. Например:
Микроядро. Микроядро — это отдельный компонент, то есть какая-то элементарная функция, которая функционирует отдельно. В модульной архитектуре все компоненты представляют собой отдельные модули, но при этом входят в состав единой программ ы ( ядра). Микроядра работают как бы отдельно. Другими словами, это более «продвинутое» модульное ядро с более высоким показателем «модульности». Микроядра более устойчивы к проблемам в системе, чем модульное ядро, так как связь между микроядрами менее выражена, нежели между модулями.
Экзоядро. Такой тип ядра предлагает только те функции, которые нужны для взаимодействия между процессорами устройства. Эти ядра подключают все необходимые процессы из внешних библиотек, а не содержат их внутри себя. Их можно сравнить с технологией API.
Гибридное ядро. При такой архитектуре «смешиваются» различные архитектуры ядер, которые мы описали чуть выше.
Ядро операционной системы: функции
Архитектура ядра влияет только на его внутренне е строение, производительность, обновления. Функции каждого вида ядра остаются неизменными. Например, ядро операционной системы выполняет следующие функции:
Управляет процессами. За этим выражением кроется огромная работ а операционной системы. Как только пользователь запускает устройство, система начинает выполнять большое количество видимых и не видимых пользователю задач. Каждая отдельная задача представляет собой процесс, которым управляет ядро операционной системы. В этом контексте можно представить ядро регулировщиком дорожного движения на перекрестке с большим потоком автомобилей, движущихся в разных направлениях. Если «регулировщик» оплошает, тогда может наступить коллапс.
Заключение
Ядро операционной системы — это «главный» набор инструкций, благодаря которому работает компьютер. Ядро ОС означает, что оно лежит в основе работы любой операционной системы. На него накладываются все возможности ОС и все дополнительное программное обеспечение. От эффективности работы ядра зависит производительность и эффективность операционной системы. От эффективности ОС зависит работа компьютерного устройства.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Ядро архитектуры
Ядро архитектуры (программное ядро) — это определенный принцип построения программного обеспечения и реализации повторного использования. До сих пор обобщенных определений дано не было, но как правило, об архитектуре ядра говорят применительно к операционным системам. Со временем, выделение так называемого ядра стали осуществлять в крупных программных комплексах. Другое возможное использование этого термина применяют когда разрабатываются некие независимые библиотеки программ (SDK), так например, говорят о графических или физических движках.
Содержание
Если вы хотите, чтобы отдельные части вашего алгоритма можно было применять в дальнейшем при построении новых программ, то единственный реальный путь к этому – вычленить претендующие на многократное использование функциональные компоненты вашей программы и оформить их в виде модулей. В результате такой деятельности формируется библиотека функций.
Пополняя библиотеку, уделяют внимание тестированию отдельных модулей, их единообразному описанию (интерфейсу), но, как правило, совершенно не беспокоясь о сохранении работоспособности прежнего состава библиотеки. Причины для беспокойства действительно нет, так как поступающие модули обычно настолько слабо связаны с остальными компонентами, что их появление не может как либо повредить соседям по библиотеки. Это происходит от того, что модули из библиотеки играют только подчиненную роль: разработчик новой программы самостоятельно пишет ведущую часть, которая время от времени обращается к таким модулям для решения частных подзадач.
Надежность ядра [ править ]
Как мы видим оформление в виде ядра, некоторых библиотек функций необходимо в первую очередь, для надежного повторного использования уже отлаженных и оттестированных алгоритмов. Причем надежность тут первично. Именно для обеспечения надежности, отказываются от простого дублирования кода. Наличие дублирования есть самая главная причина проведения рефакторинга.
Мы можем ввести два термина:
Таким образом, выделенные и оттестированные функции составляют ядро, и его использование является безболезненным как для окружения, так и для работоспособности.
Так например, примеры хорошо реализованных ядер можно найти почти исключительно только в реализации известных операционных систем (см. w:en:Kernel (computing)), или на уровне «железа» в реализации работы процессора (см. w:Микроархитектура). А многие т.н. движки, необоснованно называют ядром того или иного программного комплекса. Они, как правило, не выполняют никакой архитектурной роли, за исключением библиотеки функций, и могут рассматриваться лишь как SDK для разработки ПО.
Архитектура ядра с кольцами защиты [ править ]


Здесь мы рассмотрим понятие кольца защиты, и её применение к современной трёхуровневой архитектуре.
Кольца защиты обеспечивают информационную безопасность и отказоустойчивость на уровне аппаратного разделения системного и пользовательского уровней привилегий. Структуру привилегий можно изобразить в виде нескольких концентрических кругов. В этом случае системный режим (нулевое кольцо), обеспечивающий максимальный доступ к ресурсам, является внутренним кругом, тогда как режим пользователя с ограниченным доступом — внешним. Традиционно семейство микропроцессоров x86, начиная с x386 обеспечивает четыре кольца защиты.
На практике процессор программируется в защищенном режиме определенным образом. Для каждой локальной задачи выделяется свое локальное адресное пространство (память). В каждый момент времени в определенном регистре процессора может быть указатель только на одну из задач. Поэтому задача работает только в своем адресном пространстве и не может физически иметь доступ к другим локальным задачам. Для смены задач осуществляется т.н. переключение задач. Каждая задача имеет т.н. уровень привилегий дискриптора (DPL). Этот уровень как раз и указывает в каком кольце находится задача. Основные правила защиты по привилегиям сводятся к следующим:
Таким образом, данные находящиеся на более низком уровне с более высоких физически получить нельзя. С более высокого уровня можно вызвать программы только более низкого уровня, и то через т.н. шлюз. Сам шлюз готовится на более низком уровне, и определяет по сути, что с помощью его можно вызвать. И только обладая таким шлюзом программа более высокого уровня может вызвать программу более низкого уровня. По этой причине очень многие функции ядра операционной системы нельзя вызвать из клиентских программ, и для работы с ними нужно писать драйверы.
Вот такого рода защиту и должно обеспечивать полноценное ядро. Это, например, может означать, что сторонние разработчики не могут напрямую вызвать функцию ядра (этим ядро и отличается от библиотеки функций). Также сторонние разработчики не могут получить никаких данных из ядра, кроме тех которые непосредственно предоставляет само ядро. Но главное, управление программным ходом выполняет исключительно ядро, и при необходимости может блокировать любые клиентские подпрограммы (например, те которые работаю ошибочно или не согласно принятой архитектуре), а клиентским программам для осуществления вызовов специально предоставляет callback-функции или что тоже самое работает через события (аналог вызова через шлюз).
Таким образом, такого рода ядро реализует:
Теперь понимая, что для надежности и более четкой архитектуры нужно изолировать тем или иным образом слои приложений. Только если выше говорилось о системных слоях между операционной системой и клиентскими приложениями, то мы можем пойти далее, и изолировать слои в самом клиентском приложении.
И этих слоев как минимум два, т.н. клиент-серверная архитектура. Так сложилось, что для работы с данными повсеместно используются реляционные базы данных и, как правило, в серьезных приложениях используют или Oracle или MS SQL. Вся работа с данными преимущественно происходит посредством работы на языке SQL. Более того, как правило в хорошо разработанной архитектуре, запрещается какое-либо прямое обращение к базе данных, и вся работа с базой данных ведется посредством вызова только хранимых процедур, а уже в них на SQL так или иначе ведется работа с данными. Поэтому слой базы данных уже традиционно выделен и фактически отделен. Единственно плохо когда некоторые архитектуры, пользуясь возможностями языков программирования, прямо обращаются в серверу базы данных. В тоже время программировать пользовательский интерфейс на языке SQL невозможно. Для этого используют новейшие объектно-ориентированные языки.
Но можно пойти и еще дальше, пример более общей структуры представляет трёхуровневая архитектура. В ней также отделен сервер базы данных, но аналогично технологии MVC происходит разделение бизнес-логики и визуализации. Мы уже говорили о проблемах реализации классического MVC, но сам принцип разделения остается важным, хотя и может быть реализован более качественно. Но если в технологии MVC разделение касалось на уровне одного класса с его подклассами, то в трёхуровневой архитектуре речь идет о выделении всей визуализации в отдельную самостоятельную программу, а выделению отдельной программы (сервера) бизнес-логики. Понятно, что такое физическое разделение можно осуществить только тогда, когда логически в программе строго все было уже разделено или согласно технологии MVC, или другими более современными способами.
Процессоры, ядра и потоки. Топология систем
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.

Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».
В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.

Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.

К взлёту готов! Intel® Desktop Board D5400XS
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
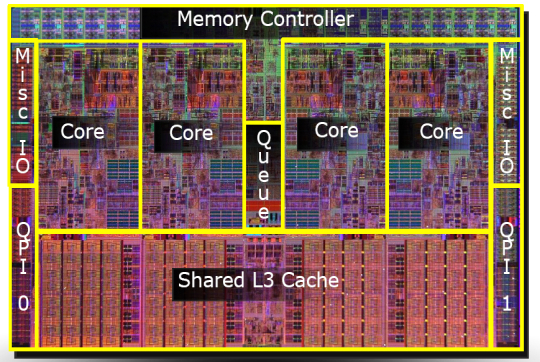
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).
Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?
Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux top показывает 4 логических процессора.
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.
В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.
Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.
Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.