
Топ-5 языков для машинного обучения
Существует великое множество языков программирования, однако не все они подходят для машинного обучения (МО). Портал Techopedia рассказывает о наиболее подходящих языках, их преимуществах и недостатках.
Специалист по вычислительной техники Стэнфордского университета Эндрю Нгом дал МО следующее определение: «наука, которая работает над тем, как научить компьютеры функционировать без явного программирования». Предпосылки к рождению науки появились в однако вплоть до начало они носили лишь теоретический характер. Настоящий прорыв произошел десятилетие назад, когда МО стало катализатором развития нескольких прорывных технологий, особенно это касается искусственного интеллекта. МО можно разбить на несколько категорий, включая контролируемое (supervised), неконтролируемое (unsupervised), полууправляемое (semi-supervised ) и обучение с подкреплением (reinforcement learning).
В то время, как контролируемое обучение для выведения взаимосвязи с выходными результатами опирается на маркированные (помеченные) входные данные, неконтролируемое МО предназначено для обнаружения закономерностей среди немаркированных входных данных. В полууправляемом (или МО с частичным привлечением учителя) применяется комбинация контролируемого и неконтролируемого обучения, тогда как обучение с подкреплением направлено на то, чтобы программы могли повторять заданную последовательность циклов или разрабатывать процессы с желаемыми результатами, избегая при этом ошибок.
МО в современной итерации востребовано во многих отраслях промышленности, растет также спрос на продукты и услуги, основой которых являются машинные алгоритмы. Предприятия применяют прогностические возможности МО, стремясь разработать предписывающие (prescriptive) методы для принятия обоснованных решений. Технология предусматривает несколько методов разработки ПО на базе машинных алгоритмов, однако самым популярным из них является задействование языков программирования.
Python. Это высокоуровневый язык программирования, который имеет множество различных способов применений, включая науку о данных и внутреннюю веб-разработку. Он был создан Python Foundation в начале и является мощным инструментом для анализа данных, широко используется в технологии больших данных. Особый статус ему придает многочисленное сообщество разработчиков МО, которое в основном сосредоточено на быстрорастущем ИИ-направлении.
Благодаря активному сообществу для Python появилось множество готовых библиотек МО. Этот язык — платформенно независимый, поэтому его можно адаптировать практически к любой операционной системе. Еще одно преимущество Python связано с его открытостью — он построен на базе технологий Open Source, поэтому разработчики могут получить доступ к любому стеку языка.
Что касается минусов Python, то поскольку это динамически типизированный язык, работа с ним в среде МО может вызывать проблемы. Одной из них является сложность отслеживания ошибок в коде, что связано с разрастанием кодовой базы программы и, соответственно, с ее сложностью. В некоторых случаях (сложные проекты для крупных организаций) аудит кода может выливаться в значительные финансовые затраты, отнимать много времени и сказываться на продуктивности проекта.
R. Этот язык программирования появился в начале и является частью проекта GNU. Он широко применяется в анализе данных и, как правило, является целевым для решения общих задач МО, таких как регрессия, классификация и формирование дерева решений. R помимо прочего пользуется популярностью среди статистиков. Как и Python, R обладает открытым исходным кодом и широко известен как язык, пакеты для работы с которым относительно легко установить, настроить и применять.
R — платформенно независимый, он хорошо интегрируется с другими языками программирования. Наряду с анализом данных, R приспособлен для визуализации данных.
Несмотря на относительную простоту интеграции с другими инструментами, R обладает рядом особенностей, которые усложняют его изучение. К ним, например, можно отнести нетрадиционные структуры данных и индексирование (которое начинается с 1 вместо 0).
R менее популярен, чем Python, поэтому массив документации, требуемый разработчикам для создания приложений в области МО, у него меньше.
JavaScript. Этот язык появился в середине как инструмент для улучшения практики веб-разработки и является одним из наиболее востребованных в этой области. JavaScript — высокоуровневый и динамически типизированный язык, гибкий и мультипарадигмальный. Применение языка в МО получило ограниченное применение, но, тем не менее, такие известные проекты, как Google Tensorflow.js, основаны на JavaScript.
Что касается плюсов JavaScript в области МО, то он открывает возможности проще вступить на неизведанную тропу для веб-разработчиков и разработчиков приложений, которые в значительной степени уже хорошо с ним знакомы. Однако нынешняя JavaScript-экосистема для МО все еще выглядит незрелой, поэтому поддержка этого типа разработки в настоящее время ограничена. Помимо этого ей недостает функций для работы с данными, которые в таких языках, как R и Python, присутствуют по умолчанию.
C++. Это самый старый среди наиболее распространенных на сегодняшний день языков программирования. Он был создан в недрах Bell Labs в начале как научно-исследовательский проект, направленный на расширение возможностей языка Си. Обладая возможностями одновременно как низкоуровневого, так и высокоуровневого языка программирования, в контексте МО C++ обеспечивает более высокий уровень контроля и эффективности, чем другие языки программирования.
Гибкость языка хорошо подходит для ресурсоемких приложений, и подмножество программ МО здесь — не исключение. Учитывая, что C++ — статически типизированный язык, он может выполнять задачи с относительно высокой скоростью.
Что касается его минусов, то основным из них является то, что для создания новых приложений на базе C++ требуется написание большого объема сложного кода, что занимает много времени и может вызвать большие трудности в обслуживании. Язык C++ определенно сложен в овладении и, создавая на нем новые проекты, начинающие программисты очень часто допускают невынужденные ошибки.
Java. За созданием Java стоит Sun Microsystems. Появившийся в середине он изначально замышлялся как высокоуровневый и объектно-ориентированный язык программирования, который во многом напоминает по структуре C++. Обладая огромной популярностью, Java может похвастаться широким спектром алгоритмов, которые очень полезны для сообщества разработчиков софта МО. Во многом Java считается одним из самых безопасных языков программирования благодаря использованию байт-кода и песочниц.
Его можно обозначить как удачную инкарнацию C++ (Java обладает большинством функционала, заложенным в C++), которая лишена недостатков последнего — проблем с безопасностью кодовой базы и сложностью компиляции.
Несмотря на все свои преимущества, Java имеет репутацию более медленного языка, чем многие другие языки программирования и в том числе C++. Кроме того, начиная с 2019 г. для написания определенных бизнес-приложений на Java требуется коммерческое лицензирование, что выльется в дополнительные расходы для предприятий.
Выводы
Python — самый популярный из всех языков программирования, применяемых в МО. Тем не менее, сбрасывать со счетов JavaScript и ряд некоторых других языков, может быть непредусмотрительно. Это связано с тем, что со временем их популярность будет расти, отражая изменения бизнес-ландшафта. Что касается тенденций программирования, то можно с уверенностью сказать, что в ближайшие несколько лет написание кода останется востребованной функцией, однако оно станет менее ориентированным на код и больше на функционал, поскольку машины сами научатся писать код.
9 языков программирования для работы с Big Data


Ментор на курсе по Data Science, автор вебинаров по Machine Learning.
Некоторые языки программирования были созданы для обработки больших массивов данных, и вокруг них сложилась целая экосистема из библиотек и фреймворков. Другие языки совсем новые, но работают гораздо быстрее. Вместе с дата-сайентистом и ментором SkillFactory Викторией Тюфяковой разбираемся, в каких случаях лучше использовать R, а в каких — MATLAB и почему Julia может потеснить Python.
Программирование нужно для всех этапов работы с большими данными, от выгрузки и очистки до проектирования баз данных и точной настройки алгоритмов машинного обучения. Вы можете выбрать любой язык из этого списка, но у каждого из них есть свои особенности и задачи, для которых он лучше подходит. Если это работа с базой данных клиентов для маркетинговой аналитики, подойдут более простые языки, а если серьезное научное исследование — то более сложные и точные.
R — для любителей статистики

R был создан для работы со статистикой. Он позволяет собирать и очищать данные, работать с таблицами, проводить статистические тесты, различные виды анализа и составлять графические отчеты. R подойдет для специалистов, знакомых с теорией вероятности, статистическими методами и математическим анализом, поэтому на первый взгляд он может показаться сложным из-за интуитивно непонятного синтаксиса.
На практике R используют:
Для R создано более 10 тыс. библиотек и расширений. Например, Ggplot2 — для визуализации данных, Bioconductor — для работы с генетической информацией, а Quanteda — для анализа текстов.
Кроме этого, R выделяют среди конкурентов высокая скорость обработки данных и открытый исходный код.
Python — популярный и понятный

Самый популярный язык программирования в рейтинге TIOBE. В работе с Big Data Python зарекомендовал себя как один из лучших инструментов наравне с R:
Для работы с данными создано несколько специализированных Python-библиотек: NumPy — для вычислений, Pandas — для анализа табличных данных, Matplotlib — для визуализации. В отличие от R, Python кроме обработки и визуализации данных активно используется для разработки сайтов, приложений и других продуктов. Также считается, что это простой язык для новичков, так как у него понятный синтаксис (мы рассказывали, с чего начать учить Python, в этой статье).
Для анализа больших данных на Python Виктория советует использовать PySpark:
« Есть библиотека PySpark из проекта Apache Spark для анализа больших данных. PySpark предоставляет множество функций для анализа больших данных на Python. Она поставляется с собственной оболочкой, которую вы можете запустить из командной строки».
Java — самый универсальный

На Java пишут сайты, разрабатывают ПО и приложения. Это многофункциональный и кроссплатформенный язык, код на котором одинаково работает на мобильных устройствах, консолях или в системе умного дома.
Он позиционируется как язык №1 в мире, которым пользуется около 9 млн разработчиков. На Java написано множество Big Data инструментов с открытым кодом (например, большая часть экосистемы Hadoop), поэтому разработчики могут на их основе создавать собственные продукты для управления данными. Универсальность — основное преимущество Java в Big Data.
«Java — это высокоэффективный скомпилированный язык, который широко используется для высокопроизводительного кодирования (ETL) и алгоритмов машинного обучения. Вот почему большие данные и Java — большие друзья».
Scala — самый недооцененный

Язык Scala не очень популярен у программистов, в рейтинге TIOBE он не входит даже в первую двадцатку. При этом в задачах по обработке данных он гораздо быстрее, чем более популярный Python. Scala способен быстро обрабатывать невероятно большие объемы информации, поэтому его используют Twitter, LinkedIn или Тинькофф.
На Scala написан фреймворк Apache Spark, важный для машинного обучения и анализа больших данных. Этот фреймворк входит в экосистему Hadoop и позволяет параллельно обрабатывать неструктурированные данные в реальном времени. Он легко взаимодействует с кодом на Java и библиотеками этого языка.
Читайте также: Big Data: что это и где применяется?
« Scala работает на JVM и у него лучше структуры параллелизма, чем у Java, поскольку Scala обеспечивает лучшую поддержку парадигмы функционального программирования».
C++ — сложный, но быстрый

C++ — язык общего назначения; это значит, что с его помощью можно решить задачу из любой области программирования. Чаще всего на нем пишут операционные системы, крупные игры и такие пакеты программ, как MS Office или Adobe. В Big Data он тоже используется в основном для создания инструментов обработки данных, а не для непосредственной работы с ними. Например, MapReduce, который сейчас входит в экосистему Hadoop, изначально был написан как раз на C++.
C++ быстрее, чем многие конкуренты (Go, R или Python). Особенно это востребовано в машинном обучении, где нужно быстро обрабатывать терабайты данных. Это единственный язык, на котором данные размером более 1 Гб могут быть обработаны за секунду.
Но при этом он действительно сложный в изучении. В 2009 году компания Google создала простой и понятный язык Go, который справлялся бы с задачами C++, высокой нагрузкой и большими объемами данных. После этого в сообществе разработчиков стали возникать споры, что лучше: учить GoLang или C++:
Вебинар Ильи Ибрагимова, Lead Golang Developers в Simplinic, о языках Go и C++
« У C/C++ лучшая производительность/скорость, когда все остальные аспекты совпадают. Большинство алгоритмов глубокого обучения реализованы на C++. На нем написано Caffe — популярное хранилище алгоритмов глубокого обучения, Minerwa от MSR China — библиотека быстрых нейронных сетей, AlexNet в CUDA ConvNet и так далее».
Go — создан Google для Big Data

Язык программирования Go создан компанией Google для работы с большими данными, поэтому сейчас он используется в большинстве продуктов компании:
По результатам опроса Go Developer 2019 Survey, 45% Go-разработчиков работают именно с базами данных. Особенность языка в том, что он производительный и может выполнять несколько функций параллельно, но при этом, как и Python, имеет простой синтаксис и низкий порог вхождения.
Data Scientist с нуля
Изучите набор инструментов, необходимый для уровня Middle. Наш карьерный центр поможет вам оформить резюме и начать проходить собеседования уже во время учебы. Дополнительная скидка 5% по промокоду BLOG.
MATLAB — для любителей научных методов

Это язык, который больше подходит для научной или производственной сферы и сложных математических вычислений. Университеты используют его в академических курсах по прикладной математике, физике и в инженерных разработках.
Считается, что рядовому разработчику не требуется этот язык. В основном его используют там, где нужны предельная точность и минимальные погрешности при работе с данными: в системах автопилота, медицине или космических исследованиях.
Julia — молодой и перспективный

Язык Julia задумывался как более простая и понятная альтернатива MATLAB. Он одним из самых молодых и современных языков, но уже вошел в топ-5 любимых языков программирования среди разработчиков по версии Stack Overflow.
По параметрам производительности Julia не уступает Python, R или MATLAB. Его используют для обработки запросов в backend, машинного обучения и даже для создания компьютерных симуляций. В будущем Julia может заменить популярный Python, но пока этот язык развивается, не имеет собственной экосистемы инструментов и большого набора библиотек, а разработчики используют для работы с ним Python-библиотеки.
*Hadoop — не язык, но активно используется

Это набор IТ-продуктов, который в основном написан на языке Java и адаптирует его к работе с Big Data. В него входят:
Так как Hadoop — это целая экосистема продуктов, его часто принимают за отдельный язык программирования. Его используют сайты и интернет-магазины с высокой пользовательской нагрузкой, такие как Google, AliExpress, Ebay, Facebook. С помощью Hadoop они анализируют поисковые запросы и другую информацию о своих пользователях.
Научитесь выявлять закономерности в данных и создавать модели для решения реальных бизнес-задач.
Инструменты машинного обучения для начинающих
Авторизуйтесь
Инструменты машинного обучения для начинающих
Прежде, чем мы с вами перейдём к инструментам машинного обучения, стоит проговорить одну простую, но важную вещь. Начинающие часто воспринимают машинное обучение как огромный цельный процесс. Нередко пугаются и впадают в ступор из-за обширности темы. Поэтому начнём с разделения процесса машинного обучения на три основных этапа:
В таком же порядке рассмотрим и инструменты, которые помогут всё это реализовать.
Языки программирования для машинного обучения
Нам понадобятся готовые библиотеки и фреймворки для машинного обучения. Мы ведь хотим научиться ездить на машине, а не конструировать её. Если вы пытаетесь подобрать «тот, самый подходящий» язык, то не переживайте: в любом современном языке программирования уже написаны такие инструменты, поэтому берите любой, который нравится (или знаете).
Но если мы начнём рассказывать обо всех языках в одной статье, то она будет очень длинной. Поэтому дальше будем рассматривать всё, что связано именно с Python, популярность которого стабильно растёт на протяжении вот уже нескольких лет благодаря своей гибкости, хорошей читаемости и простоте в обучении. Написанные под него библиотеки машинного обучения — самые популярные на момент выпуска статьи.
Инструменты для сбора, обработки и визуализации данных
Здесь мы собираем данные с различных сайтов и создаём датасет, который потом используем для обучения алгоритма. Сбор данных с сайтов ещё называют веб-скрейпингом (ранее мы подробно рассказывали об инструментах для веб-скрейпинга).
После того, как собрали данные, их нужно обработать, чтобы избавиться от ошибок, шума и несогласованностей, которые приведут к ситуации «мусор на входе — мусор на выходе». Это очень важно, так как от корректности данных будет зависеть точность результатов алгоритма.
3–5 декабря, Онлайн, Беcплатно
Визуализация поможет определить линейность структуры данных, существенные признаки и аномалии. Для этих задач можно воспользоваться готовыми веб-сервисами, либо написать собственный код.
После того как мы почистили наш датасет, нужно поделить его на 80% — для обучения модели, — и 20% — для её проверки и тестирования.
pandas: библиотека для обработки и анализа данных
Она построена поверх NumPy, о котором поговорим чуть дальше. Это наши группировки, сортировки, извлечения и трансформации. Для работы с файлами CSV, JSON и TSV pandas превращает их в структуру данных DataFrame со строками и столбцами. Выглядит, как обычная таблица в Excel, и работать с ней легче, чем с for-циклами для прохода по элементам списков и словарей.
Tableau, Power BI, Google Data Studio: простая онлайн-визуализация без кода
Инструменты для бизнес-аналитики и людей без особых навыков программирования. Ключевое слово здесь — визуализация. Загружаем датасет и пользуемся встроенными функциями, фильтрами и аналитикой в реальном времени. Эти сервисы быстро собирают инсайты и представляют их в наглядной форме. И Tableau, и Power BI, и Google Data Studio имеют как платные подписки, так и бесплатные версии (само собой, с ограничениями).
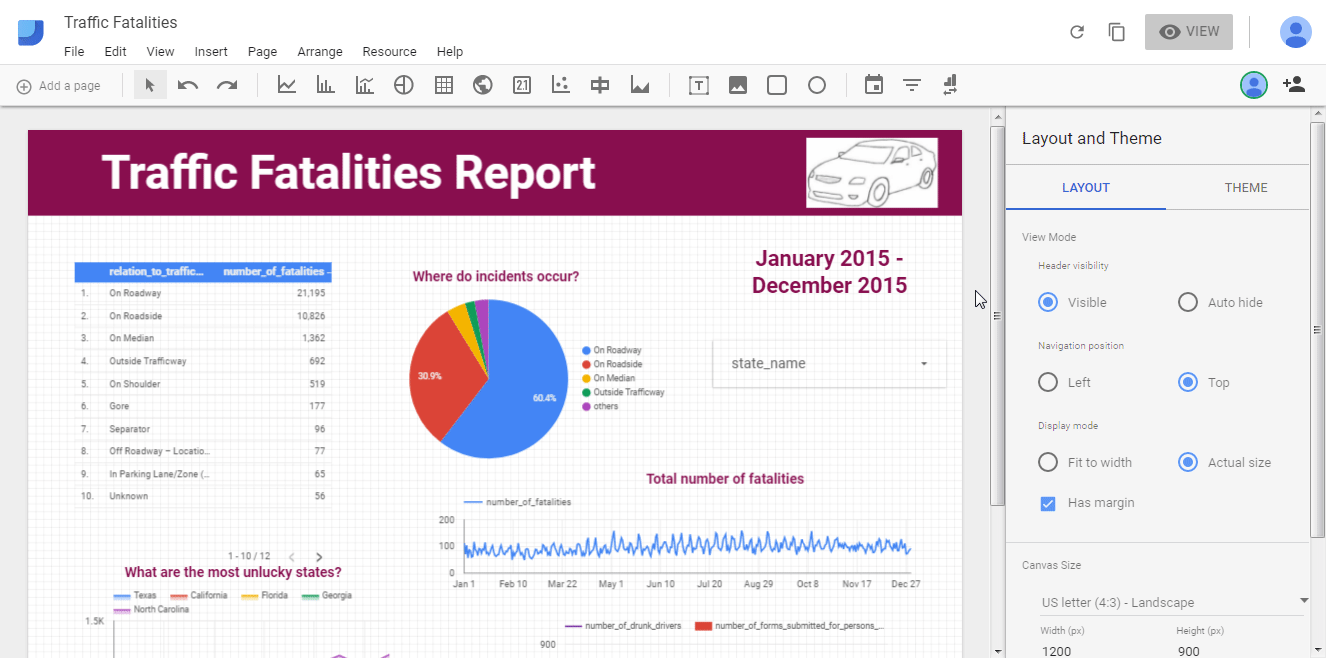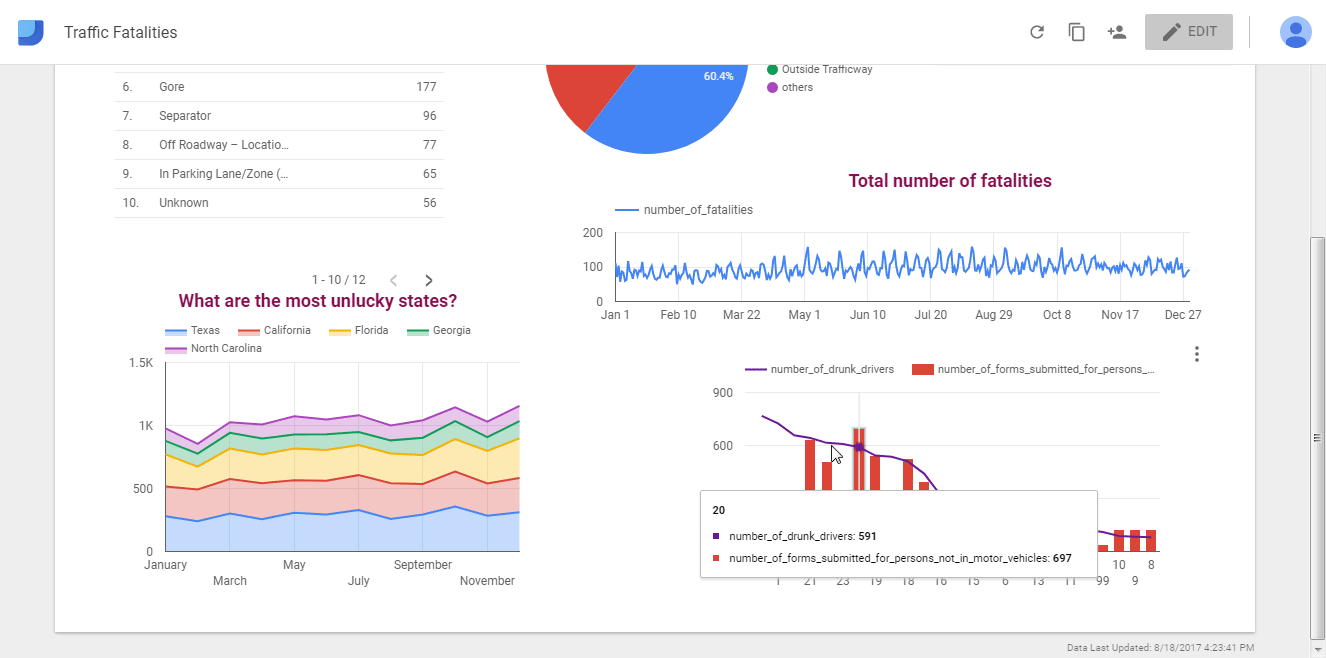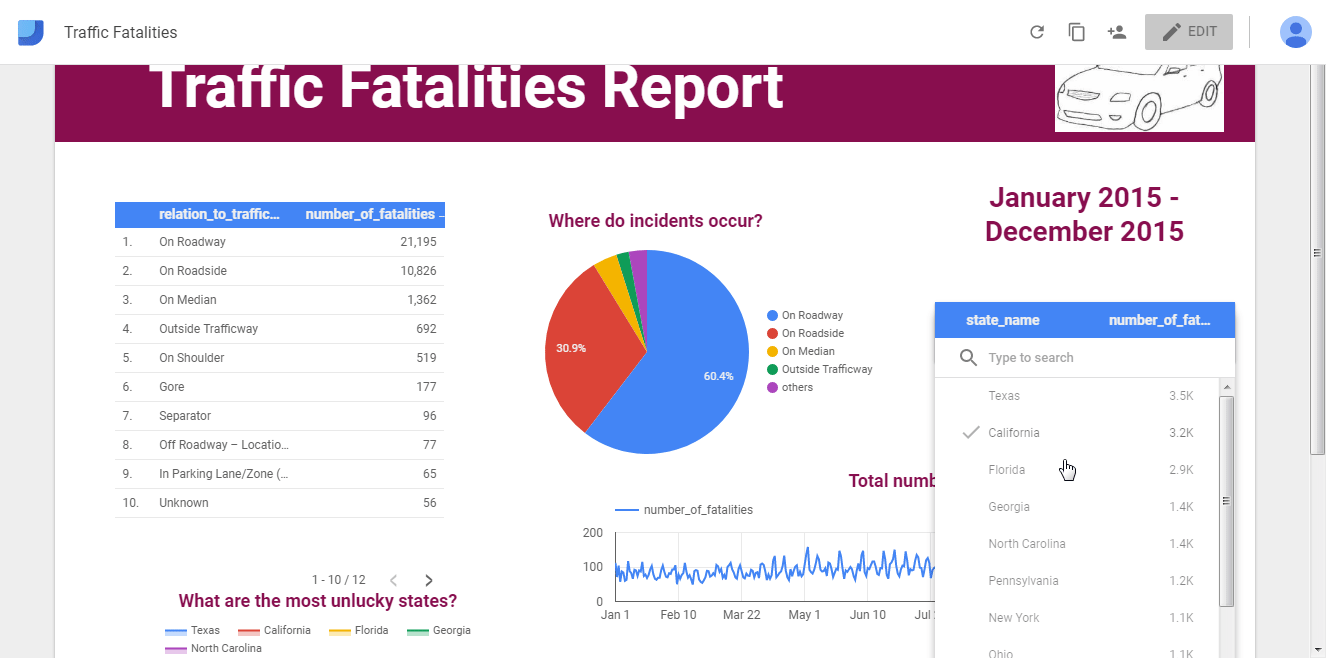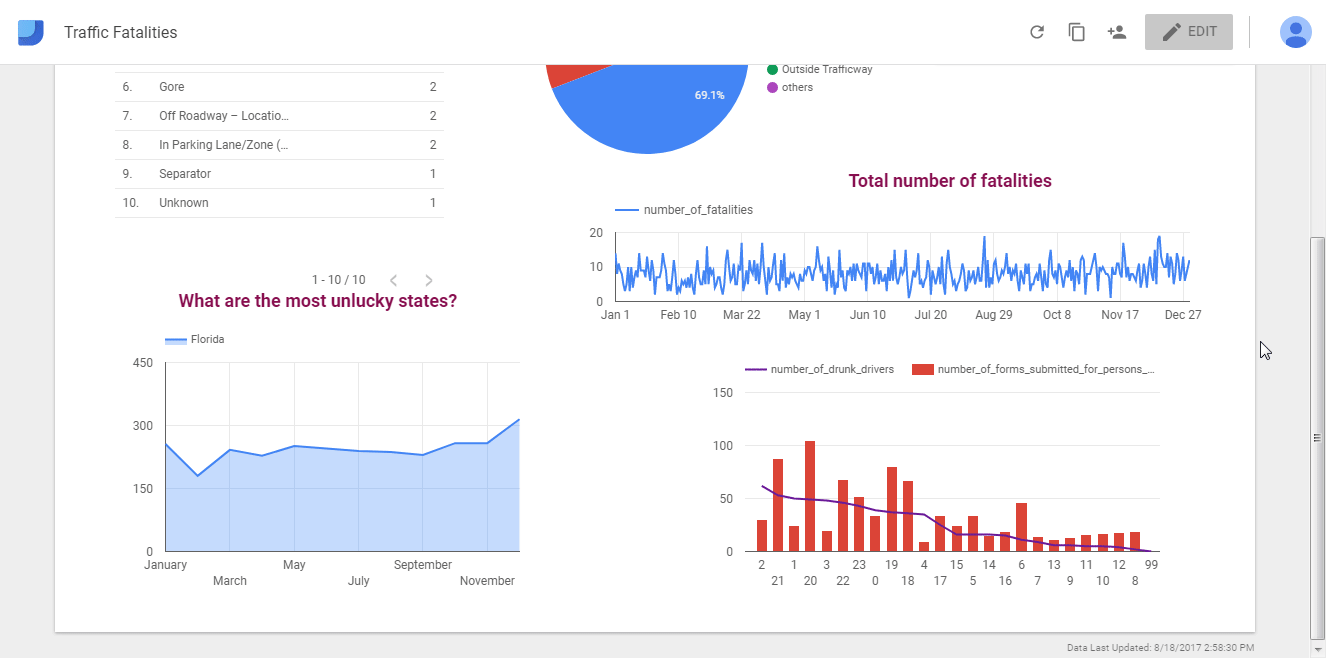
Matplotlib: библиотека для построения 2D-графиков
Matplotlib в связке с библиотеками seaborn, ggplot и HoloViews позволяет строить разнообразные графики: гистограммы, диаграммы рассеяния, круговые и полярные диаграммы, и много других. Для большинства из них достаточно написать всего пару строк.
Интерактивные среды разработки
Эти инструменты часто используются для Data Science и машинного обучения. Веб-среда (её также называют «notebook») позволяет разработчикам на лету тестировать небольшие части кода, проверять функциональность и разные гипотезы. Тем не менее, при желании в ней можно поместить и целый проект.
Jupyter Notebook: интерактивное моделирование
Простая в использовании бесплатная интерактивная веб-оболочка. Помимо Python, Jupyter Notebook поддерживает более чем 40 языков программирования. В нём удобно экспериментировать с новыми идеями в режиме «зашёл-сделал-вышел», писать документацию и создавать аналитические отчёты. Напоминает IDE, но по функциональности, хоть и достаточно широкому, до неё не дотягивает.
Среди инструментов для машинного обучения, и в целом Data Science, Jupyter хорош благодаря быстрому анализу, моделированию и визуализации данных. Результаты можно экспортировать во множество форматов, в числе которых — широко распространённые PDF и HTML.
Kaggle: сообщество Data Science
Kaggle также предоставляет интерактивную среду разработки. Разница в том, что всего один клик отделяет вас от целого сообщества Data Science и машинного обучения. Здесь можно найти готовые датасеты, модели и даже программный код для решения разных задач.
Также крупные коммерческие компании часто проводят здесь конкурсы и разыгрывают призовой фонд в обмен на бесплатную лицензию на использование интеллектуальной собственности (алгоритма и программного обеспечения) победившего участника.
Фреймворки и библиотеки для общего машинного обучения
Обучение модели делится на две большие категории: с учителем и без. В первом случае мы маркируем датасет, объясняя алгоритму машинного обучения, где правильный ответ, а где — нет. Так данные можно представить таблицей соответствий «элемент-категория».
Во втором случае алгоритм сам вынужден искать признаки и закономерности, так как в датасете мы даём данные без уточняющей информации. Датасет представлен сплошным потоком данных нужного типа: текста, картинок и др.
Для каждой категории используются свои алгоритмы машинного обучения (кластеризация, классификация, регрессия, ассоциация). Оптимальный выбор зависит от задачи, сложности модели, размера и типа данных.
Имейте в виду, что обучение и отладка собственной модели — долгий и затратный процесс. Очень вероятно, что кто-то уже решал похожую задачу и подготовил модель. Поэтому стоит поискать, воспользоваться реализованной архитектурой и переучить алгоритм под ваши данные. Но чем больше ваша задача отличается от той, что решает готовая модель, тем больше нужно её переучивать и менять параметры.
NumPy: готовые вычислительные алгоритмы и линейная алгебра для машинного обучения
Данные в машинном обучении представлены числовыми массивами. Даже если мы работаем с картинками или естественной речью, они должны быть преобразованы в числовые массивы. В NumPy уже реализовано всё необходимое для этого: преобразование Фурье, генерация случайных чисел, перемножение матриц и другие сложные операции. Вам остаётся только пользоваться.
NLTK: разбираем естественный язык на части
Один из ведущих инструментов для обработки естественного языка. По аналогии с тем, как NumPy упрощает линейную алгебру, NLTK упрощает парсинг текста, анализ тональности, структуры предложений и всё, что с этим связано.
scikit-learn: всё гениальное просто
Позиционируется как простая библиотека с кучей примеров на официальном сайте, из-за чего хорошо подходит новичкам. Но это не значит, что для серьёзных проектов он не годится.
Spotify, например, сделали свою рекомендательную систему как раз с помощью scikit-learn. Работает в связке с SciPy, NumPy и Matplotlib. Все базовые функции типа кластеризации, классификации и регрессии, разумеется, на месте.
Фреймворки глубокого обучения и моделирования нейросетей
Упомянутые инструменты машинного обучения позволяют нам получить модель, способную выполнять сравнительно простые задачи. Однако дальше речь пойдёт о глубоком машинном обучении нейронных сетей. Здесь для принятия более сложного решения алгоритм учитывает различные факторы, пропуская входящие данные через множество слоёв нейронов.
Само собой, для этого нужно больше вычислительной мощности и данных для обучения. Например для GPT-3 OpenAI насобирали датасет из 45 ТБ текстовых данных и отфильтровали его до 570 ГБ. Обучение модели стоило им миллионы долларов. При этом использовали они даже не весь текст. Поэтому в проектах поменьше обучение часто делегируют облачным сервисам типа Google Cloud или Amazon AWS.
На рынке инструментов глубокого машинного обучения классическая ситуация: бодаются два мастодонта — фреймворки PyTorch и TensorFlow. Раньше в них были существенные отличия. Но разграничения постепенно стираются с тем, как они перенимают друг у друга лучшие особенности.

PyTorch: король исследований
Прост в изучении и понимании, хорошо дружит с остальной питоновской экосистемой. Поэтому к новичкам PyTorch относится мягко. Отладка проходит на интуитивном уровне: ставим брейкпоинт куда угодно в коде и смотрим значения переменных. Ещё исследователям нравятся динамические графы, благодаря которым можно менять поведение модели на ходу. Всё это позволяет проверять различные теории и подходы на небольших датасетах без долгих задержек.
TensorFlow: король продакшена
Главное отличие — в подходе. Если PyTorch правит в академической среде, то TensorFlow изначально ориентирован на рынок. Да, графы у него статические; для отладки нужно учиться работать с отдельным дебагером tfdbg; а его API меняли кучу раз, ломая при этом обратную совместимость. Но он заточен для решения задач именно бизнеса: пропускать через себя огромные массивы данных при хорошей производительности и с возможностью использовать модели на мобильных устройствах без костылей и бубнов. Хотя и PyTorch уже двигается в этом направлении.
Keras: «С++ машинного обучения»
Первое, что новичок замечает в TensorFlow — это сложность. Ведь буквально всё находится и происходит внутри графа — и операции, и числа. А значит, не так, как обычно.
Keras — более высокоуровневый интерфейс для TensorFlow, CNTK, Theano, MXNet и PlaidML. Простыми словами, он создан, чтобы стать языком «С++ машинного обучения» для низкоуровневых фреймворков. Новичок может не думать, как реализовать тензорную алгебру, построить модель и прочее. Он просто воспользуется готовыми строительными блоками. Мыслительный ресурс освобождается, из-за чего начинающие специалисты быстрее учатся, а более опытные разработчики больше концентрируются на стратегических задачах.
TensorBoard: козырь в рукаве TensorFlow
Человеку непросто держать и анализировать в голове все данные. Нативная визуализация графов в браузере с разными метриками и возможностью отслеживать работу моделей — то, чего нет у PyTorch. Конечно, можно сказать про Visdom, но по возможностям он сильно уступает TensorBoard. Поэтому в PyTorch приходится часто использовать Matplotlib для визуализации и писать графики самому.
В этом аспекте TensorFlow выигрывает. Помимо метрик, разные структуры можно окрашивать в зависимости от используемого для вычислений устройства (CPU или GPU), подсвечивать узлы для отслеживания входящих данных, отображать несколько графов одновременно. Словом, всё, чтобы мониторить работу было легко и удобно.
Какие ещё инструменты машинного обучения вы бы посоветовали? Расскажите в комментариях!