
Компиляция (программирование)
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык. [3]
Содержание
Виды компиляторов [2]
Виды компиляции [2]
Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Для каждой целевой машины (Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
В конкретных реализациях компиляторов эти этапы могут быть раздельны или совмещены в том или ином виде.
Трансляция и компоновка
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить и компоновку (то есть содержал две части — транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
Примечания
См. также
Литература
Полезное
Смотреть что такое «Компиляция (программирование)» в других словарях:
Компиляция — Компиляция: В Викисловаре есть статья «компиляция» Компиляция (литература) (лат. … Википедия
Условная компиляция — В информатике, препроцессор это компьютерная программа, принимающая данные на входе, и выдающая данные, предназначенные для входа другой программы, например, такой как компилятор. О данных на выходе препроцессора говорят, что они находятся в… … Википедия
Объектно-ориентированное программирование — Эта статья во многом или полностью опирается на неавторитетные источники. Информация из таких источников не соответствует требованию проверяемости представленной информации, и такие ссылки не показывают значимость темы статьи. Статью можно… … Википедия
JIT-компиляция — Just in time compilation (JIT, компиляция «на лету»), dynamic translation (динамическая компиляция) технология увеличения производительности программных систем, использующих байт код, путём компиляции байт кода в машинный код… … Википедия
Сравнение языков программирования — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. Условные обозначения … Википедия
Пайтон — Python Класс языка: функциональный, объектно ориентированный, императивный, аспектно ориентированный Тип исполнения: интерпретация байт кода, компиляция в MSIL, компиляция в байт код Java Появился в: 1990 г … Википедия
ГОСТ 19781-90: Обеспечение систем обработки информации программное. Термины и определения — Терминология ГОСТ 19781 90: Обеспечение систем обработки информации программное. Термины и определения оригинал документа: 9. Абсолютная программа Non relocatable program Программа на машинном языке, выполнение которой зависит от ее… … Словарь-справочник терминов нормативно-технической документации
Паскаль (язык) — Pascal Семантика: процедурный Тип исполнения: компилятор Появился в: 1970 г. Автор(ы): Никлаус Вирт Паскаль (англ. Pascal) высокоуровневый язык программирования общего назначения. Один из наиболее известных языков программирования, широко… … Википедия
Паскаль (язык программирования) — Эта статья или раздел нуждается в переработке. В Паскале нет модулей, ООП и прочих новомодных веяний. Описание расширений должно присутствовать только в статьях о соответ … Википедия
D (язык программирования) — У этого термина существуют и другие значения, см. D. D Семантика: мультипарадигменный: императивное, объектно ориентированное, обобщённое программирование Тип исполнения: компилятор Появился в: 1999 Автор(ы) … Википедия
Что такое компилятор?
В этом гайде вы узнаете о том, что такое компилятор и как он работает. Мы разберем этапы компиляции и от чего зависит выбор подходящего компилятора. Этот материал поможет лучше понять, как компьютер выполняет программный код и почему иногда код не компилируется.
Зачем нужен компилятор?
Процессор — самая важная часть компьютера. Он обрабатывает информацию, выполняет команды пользователя и следит за работой всех подключенных устройств. Но процессор может разобрать только машинный код — набор 0 и 1, которые записаны в определённом порядке.
Почему именно 0 и 1? В процессор поступают электрические сигналы. Сильный сигнал обозначается цифрой 1, а слабый — 0. Набор таких цифр обозначает какую-то команду. Процессор ее распознает и выполняет.
Программы для первых компьютеров выглядели как огромные наборы 0 и 1. Чтобы записать такую программу, инженеры пользовались гибкими картонными карточками — перфокартами. Цифры на перфокарте записывались поочередно, в несколько строк. Чтобы записать 1, программист делал отверстие в карте. Места без отверстия обозначали 0.

Компьютер считывал перфокарту специальным устройством и выполнял записанную команду. Для одной программы составляли сотни перфокарт.
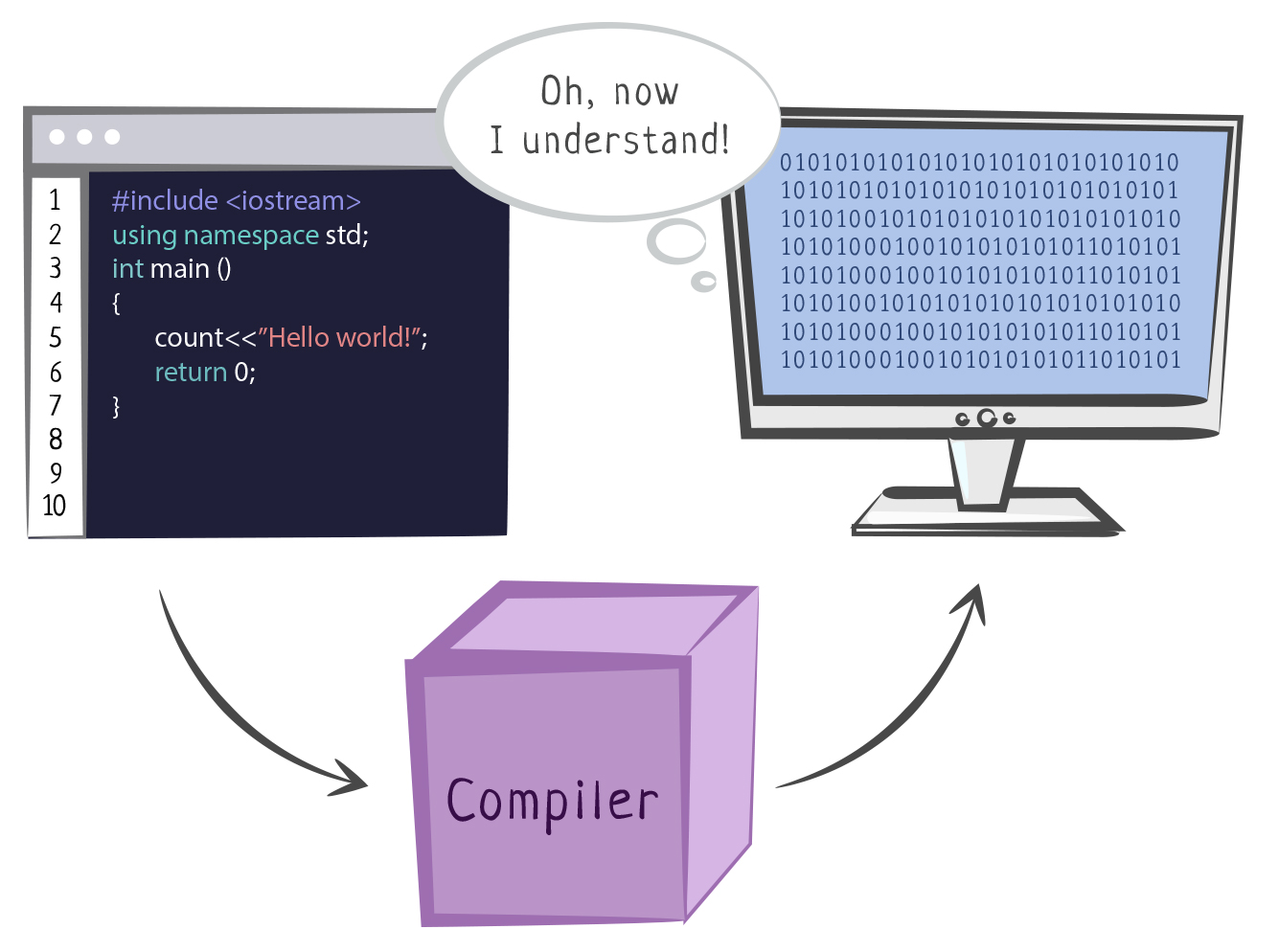
Писать их было долго и сложно, поэтому инженеры стали создавать языки программирования, обозначая команды словами и знаками. Для того, чтобы процессор понимал, какие команды записаны в программе, программисты создали компилятор — программу, которая преобразует программный код в машинный.
Как работает компилятор?
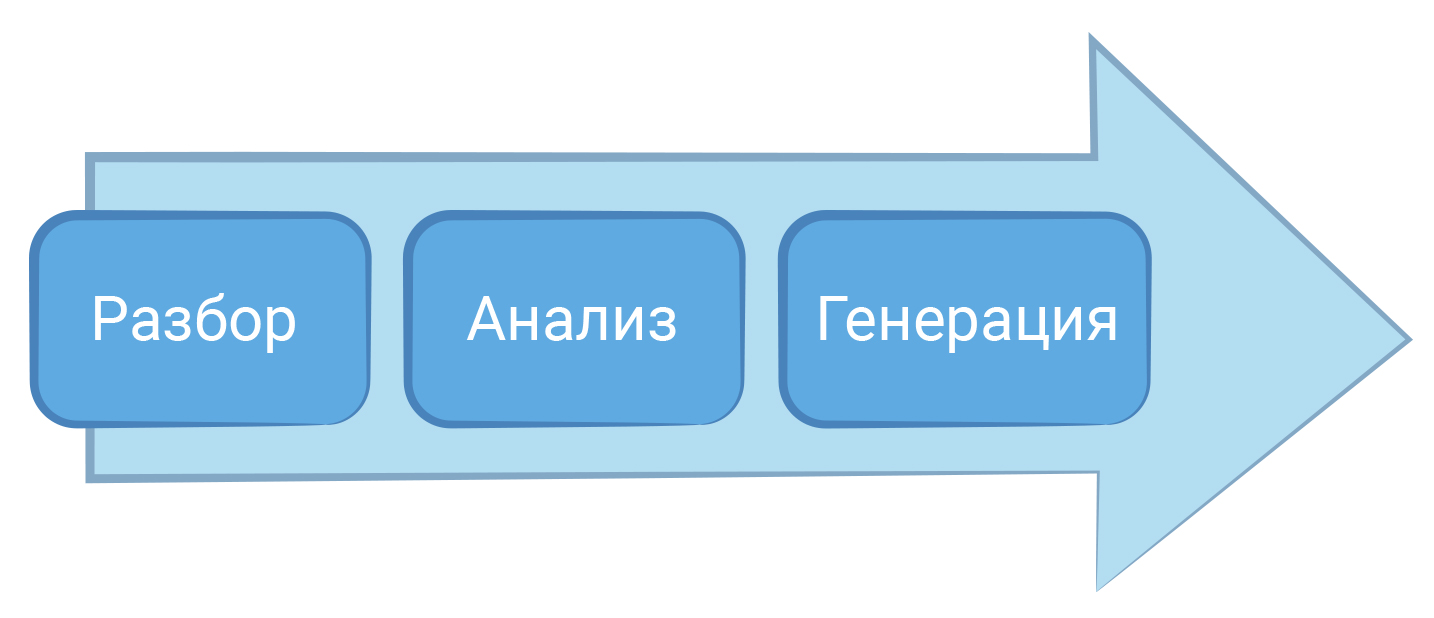
Преобразование программного кода в машинный называется компиляцией. Компиляция только преобразует код. Она не запускает его на исполнение. В этот момент он “статически” (то есть без запуска) транслируется в машинный код. Это сложный процесс, в котором сначала текст программы разбирается на части и анализируется, а затем генерируется код, понятный процессору.
Разберём этапы компиляции на примере вычисления периметра прямоугольника:
После запуска программы компилятору нужно определить, какие команды в ней записаны. Сначала компилятор разделяет программу на слова и знаки — токены, и записывает их в список. Такой процесс называется лексическим анализом. Его главная задача — получить токены.
Компилятор должен понять, какие токены в списке связаны с токен-оператором. Чтобы сделать это правильно, для каждого оператора строится специальная структура — логическое дерево или дерево разбора.
Так операция P = 2*(a + b) будет преобразована в логическое дерево:
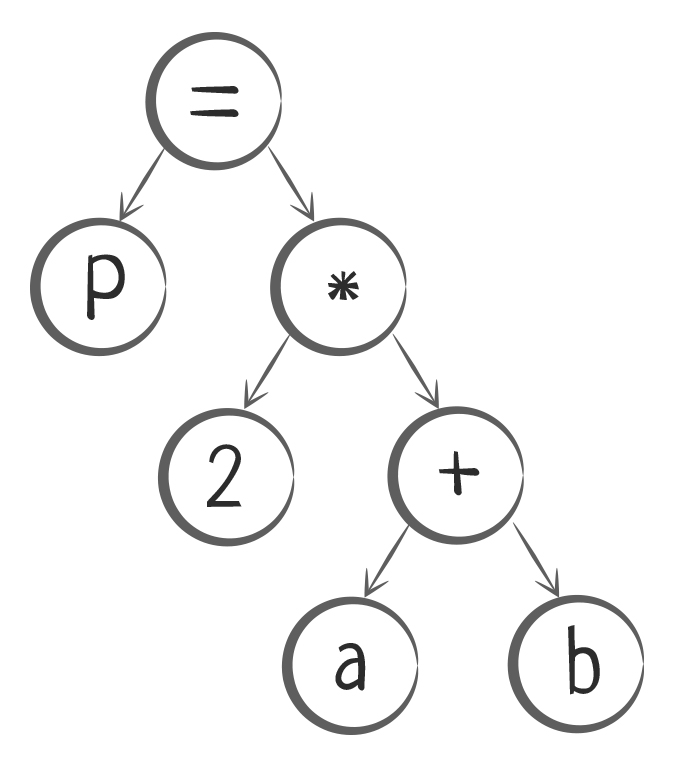
Теперь каждое дерево нужно разобрать на команды, и каждую команду преобразовать в машинный код. Компилятор начинает читать дерево снизу вверх и составляет список команд:
Компилятор еще раз проверяет команды, находит ошибки и старается улучшить код. При успешном завершении этого этапа, компилятор переводит каждую команду в набор 0 и 1. Наборы записываются в файл, который сможет прочитать и выполнить процессор.
На чем написан компилятор?
В 1950-е годы группа разработчиков IBM под руководством Джона Бэкуса разработала первый высокоуровневый язык программирования Fortran, который позволил писать программы на понятном человеку языке. Помимо языка, инженеры работали и над компилятором. Он представлял собой программу с набором исполняемых команд, которая могла компилировать другие программы на Fortran, в том числе и улучшенную версию себя.
В дальнейшем язык Fortran и его компилятор использовали, чтобы написать компиляторы для новых языков программирования. Такой подход используют программисты и в настоящее время. Писать машинный код долго и неудобно. К тому же, для современных процессоров он может отличаться. Придется писать несколько версий одного и того же компилятора для разных компьютеров. Быстрее и проще написать компилятор на существующем языке программирования. Для этого разработчики выбирают удобный язык и пишут на нем первую версию своего компилятора. Он будет более универсальным для компьютеров и легко скомпилирует улучшенную версию себя. 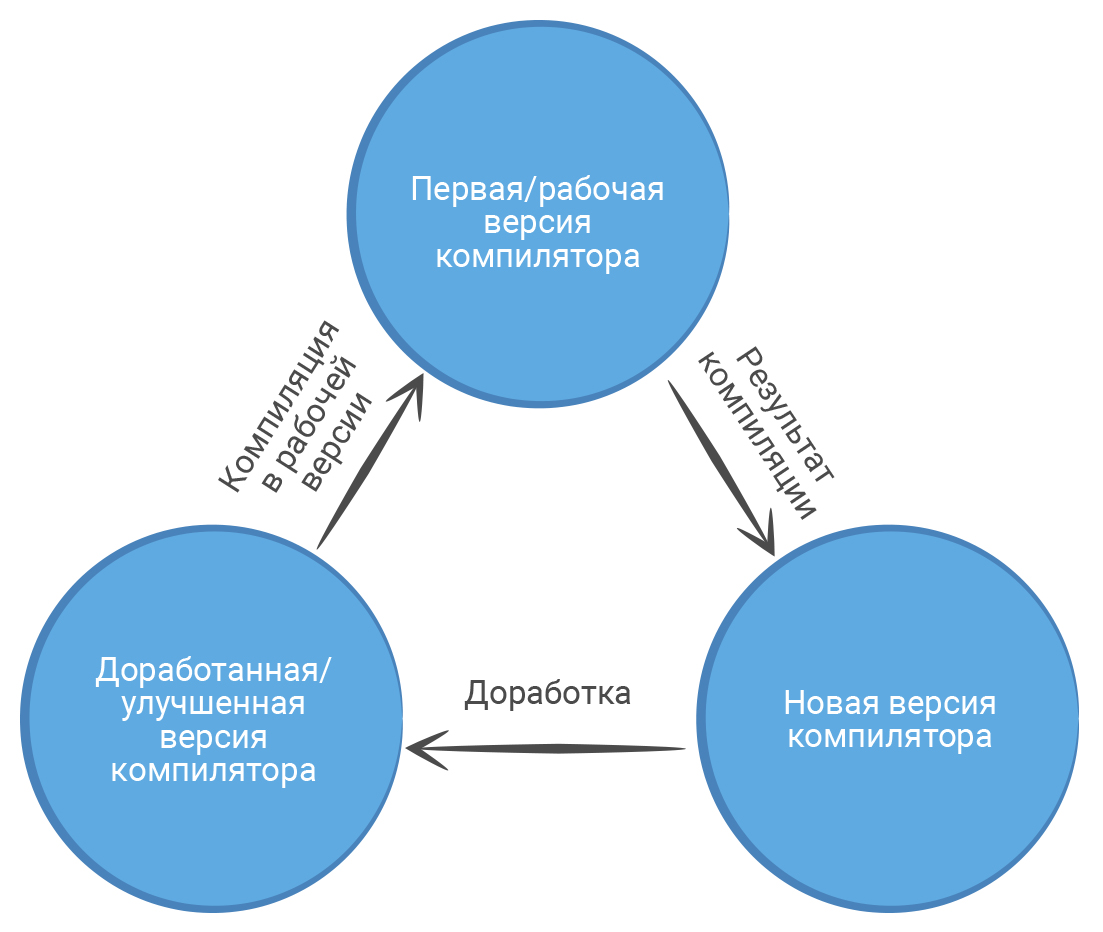
Какие бывают компиляторы?
Ни один компилируемый язык программирования не обходится без компилятора. Некоторые компиляторы работают с несколькими языками программирования. Но программист должен учитывать еще и параметры компьютера, на котором программа будет запускаться.
Дело в том, что современные процессоры отличаются друг от друга устройством, поэтому машинный код для одного процессора будет понятен, а для другого нет. Это касается и операционных систем: одна и та же программа будет работать на Windows, но не запустится на Linux или MacOS. Поэтому нужно пользоваться тем компилятором, который работает с нужным процессором и операционной системой.
Если программа будет работать на нескольких операционных системах, то нужен кросс-компилятор — компилятор, который преобразует универсальный машинный код. Например, GNU Compiler Collection(сокращенно GCC) поддерживает C++, Objective-C, Java, Фортран, Ada, Go и поддерживает разную архитектуру процессоров.
Начинающие программисты даже не знают о наличии компилятора на компьютере. Они пишут программы в интегрированной среде разработки, в которую встроен компилятор, а иногда и не один. В этом случае, выбор компилятора делает среда, а не программист. Например, MS Visual Studio поддерживает компиляторы для операционных систем Windows, Linux, Android. Выбирая тип проекта, Visual Studio определяет процессор и операционную систему компьютера, и после этого выбирает подходящий компилятор.
Какие ошибки может определить компилятор?
Когда компилятор анализирует текст программы, он проверяет, соответствует ли запись оператора стандартам языка. Если найдено несоответствие, то компилятор выводит об этом информацию пользователю в виде ошибки. Когда вся программа разобрана, пользователь видит список ошибок, которые есть в коде, и может их исправить. Пока программист не исправит ошибки, компилятор не перейдет к следующему этапу — генерации машинного кода для процессора. Чаще всего компилятор показывает пользователю:
Иногда компилятор определяет код, который при выполнении дает неправильный результат. Но преобразовать такую программу в машинный код все-таки можно. В этом случае компилятор показывает пользователю предупреждение. Такая реакция компилятора больше похожа на рекомендации, но на них стоит обратить внимание. Программист сам решает оставить код с предупреждением или изменить программу. Анализируя текст программы, компилятор не только ищет ошибки, но еще и упрощает ее код. Такой процесс называется оптимизацией. Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Выводы и рекомендации
Компилятор — переводчик между программистом и процессором. Он преобразует текст программы в машинный код, определяет ряд ошибок в программе и оптимизирует ее работу. Выбирая, где компилировать программу, важно помнить о том, что машинный код для процессоров и операционных систем будет разным, и подобрать правильный компилятор. Чем точнее компилятор определит команды, тем корректнее и быстрее будет работать программа. Для этого следуйте простым рекомендациям:
Частые вопросы
Чем компилятор отличается от интерпретатора?
Компилятор это программа, которая выполняет преобразование текста программы в другое представление, обычно машинный код, без его запуска, статически. Затем эта программа уже может быть запущена на выполнение. Интерпретатор сразу запускает код и выполняет его в процессе чтения. Промежуточного этапа как в компиляции нет.
Введение в компиляцию. Структура компилятора. Процесс компиляции.
Язык программирования – это искуственный язык, созданный для взаимодействия с машиной, в частности, с компьютером. ЯП используются для написания программ, которые управляют машиной и/или выражают алгоритмы.
Первые ЯП были созданы задолго до появления компьютеров и управляли поведением, скажем, самоиграющих пианино или автоматических ткацких станков.
Многие ЯП имеют императивную форму, т.е. описывают последовательность операций. Другие могут иметь декларативную форму, т.е. описывают результат, а не то, как его получить.
Некоторые языки определяются стандартом (C,C++,Haskell, и др.). Другие не имеют формального описания, и наиболее широко распространенная реализация используется в качестве эталона.
Описание ЯП обычно делится на две части: синтаксис, т.е. форма, и семантика, т.е. значение.
Синтаксис в свою очередь подразделяется на лексику и грамматику.
Лексика определяет какие “слова” могут быть в языке. Это включает названия переменных, функций, числовые константы, строки, и т.п., а так же управляющие символы языка. Грамматика определяет каким образом эти “слова” комбинируются в более сложные выражения.
Не все синтаксически корректные программы являются семантически корректными. Например:
Семантика же подразделяется на статическую, динамическую, и систему типов.
определяет статические свойства языка, выходящие за рамки синтаксиса. Например, статическая семантика может определять, что все идентификаторы должны быть определены перед использованием, или что вызов функции должен принимать столько же аргументов, сколько указано в её определении (ни то ни другое не является, вообще говоря, обязательным)
определяет стратегию выполнения программы. Она определяет, каким образом исполняются инструкции, порядок их исполнения, значение управляющих структур и т.д.
определяет каким образом ЯП классифицирует значения и выражения, как эти типы взаимодействуют и каким образом ЯП может манипулировать ими. Система типов является практическим приложением теории категорий. Цель системы типов – проверка программы на корректность (до какой-то степени). Любая система типов, отвергая некорректные программы, будет так же отвергать некоторый процент корректных (хотя вероятно необычных) программ. Чтобы обойти это ограничение, ЯП обычно имеют некие механизмы для выхода из ограничений системы типов. В большинстве случаев, указание корректных типов ложится на совесть программиста. Однако некоторые ЯП (обычно функциональные) умеют выводить типы исходя из семантики, и таким образом освобождают программиста от необходимости явно указывать типы.
Динамическая семантика может определяться различными способами. Наиболее распространёнными являются операционная семантика и денотационная семантика.
Операционная семантика способ описания семантики, при котором для описания поведения используется набор аксиоматических определений синтаксических конструкций языка и логических правил вывода (вида “если, то”). Выделяют операционную семантику с малым шагом, когда подробно определяется каждый шаг вычисления для выражений, и операционную семантику с большим шагом, когда определяется конечный результат выражений. Денотационная семантика способ описания семантики, при котором выражениям языка ставятся в соответствие какие-то математические объекты с априори известной семантикой, т.е. смысл языковых конструкций ставится в соответствие конструкциям математическим.
Введение в компиляцию
Компиляция – это трансляция (преобразование) текста программы, написанного на одном языке (исходном), в эквивалентный (сохраняющий семантику) текст на другом языке (целевом).
Компилятор – это программа, читающая текст программы на исходном языке и компилирующая его.
Альтернативным подходом является интерпретация, т.е. непосредственное выполнение операций, указанных в исходном тексте программы.
Интерпретатор – программа, читающая исходный текст, и интерпретирующая его.
Кроме того, компилятор может производить статический анализ исходного кода программы и сообщать об ошибках и выводить предупреждения о потенциальных проблемах.
Целевой язык может быть машинным языком, в таком случае результат работы компилятора может быть выполнен исполнительным устройством непосредственно. Целевой язык может быть также другим языком программирования (транс-компиляция) или машинным языком для некой виртуальной машины (такой язык обычно называется байт-кодом). Байт-код в свою очередь выполняется программой-интерпретатором байт-кода.

Условная схема компиляции

Условная схема интерпретации

Условная схема компиляции в байт-код
Вообще говоря, для создания исполняемой программы на целевом языке могут потребоваться другие программы и компоненты.

Структура компилятора. Процесс компиляции
Процесс компиляции обычно разделяется на две фазы: анализ и синтез.
В фазе анализа происходит чтение исходного текста программы, затем этот текст разбивается на элементарные блоки, на них накладывается грамматическая структура, и создаётся промежуточное представление исходного текста и собирается другая информация об исходном тексте. На этой фазе так же возможен статический анализ исходного текста.
В фазе синтеза, на основе промежуточного представления и прочей информации, строится представление исходной программы в целевом коде. На этой фазе так же возможны преобразования целевого кода, называемые оптимизациями.
Кроме того, между анализом и синтезом может находиться фаза преобразований промежуточного кода, называемая машинно-независимой оптимизацией.

Лексический анализ
Первая фаза компиляции называется лексическим анализом или сканированием.
Лексический анализатор соответственно так же называется лексером или сканером.
Лексический анализатор сканирует входной поток символов (исходного текста программы) и выделяет значащие последовательности символов, называемые лексемами.
Для каждой лексемы анализатор выводит токен, представляющий из себя комбинацию абстрактного символа (названия типа токена) и произвольного набора атрибутов. Часто в качестве “набора атрибутов” выступает ссылка в глобальную таблицу, называемую таблицей символов.
Синтаксический анализ
Вторая фаза – синтаксический анализ или разбор, парсинг (от англ. parsing).
Синтаксический анализатор соответственно называется так же парсером.
Парсер строит из токенов, полученных от лексера, древовидное промежуточное представление (часто неявно), отражающее грамматическую структуру исходного кода. Примером такого представления является синтаксическое дерево, где узлы представляют операцию, дочерние узлы – аргументы этой операции.
Например, синтаксическое дерево арифметического выражения \(1+2*3\) может иметь вид:


Семантический анализ
Семантический анализатор использует синтаксическое дерево для проверки исходной программы на корректность.
На этом же этапе происходит проверка типов, и информация о типах переменных записывается в атрибуты соответствующих узлов синтаксического дерева.
Если спецификация языка разрешает неявное приведение типов, на этом этапе синтаксическое дерево может быть переписано с добавлением явных операций приведения типов.
Генерация промежуточного кода
В процессе компиляции, могут создаваться несколько промежуточных представлений, в частности, синтаксическое дерево.
Как правило, после завершения синтаксического и семантического анализа, значительная часть высокоуровневой информации (типы, названия переменных, многие управляющие конструкции и т.п.) далее не требуется, в связи с чем многие компиляторы по достижении этой фазы генерируют более низкоуровневое представление, называемое обычно промежуточным кодом.
Основными требованиями к промежуточному коду являются, с одной стороны, простота его получения из синтаксического дерева, и с другой стороны, простота генерации на его основе машинного кода.
Как следствие, часто в качестве промежуточного кода используется последовательность инструкций для некой абстрактной вычислительной машины.
На этом этапе обычно принимаются решения о распределении памяти для хранения значений переменных.
Машинно-независимая оптимизация
На фазе машинно-независимой оптимизации, промежуточный код преобразуется с целью “улучшения” без изменений наблюдаемого поведения (в соответствии со спецификацией языка 1 ). Под “улучшением” обычно понимается “ускорение”, но иногда возможны другие критерии, например “код меньшего размера” или “меньшее потребление памяти”.
Часто, алгоритм первичной генерации промежуточного кода достаточно простой, поэтому без фазы оптимизации, код оказывается достаточно неэффективным.
Объём работы, проделываемый различными компиляторами на этом этапе может сильно отличаться. Большинство распространённых на рынке компиляторов являются “оптимизирующими” и значительная часть времени компиляции уходит именно на оптимизацию (обычно есть способ отключить оптимизацию при необходимости).
Генерация целевого кода
Генератор целевого кода, получая на вход промежуточный код, отображает каждую команду промежуточного кода в одну или несколько команд целевого.
Кроме того, генератор целевого кода занимается задачей распределения регистров исполнительного устройства.
Машинно-зависимая оптимизация
Шаг машинно-зависимой оптимизации преобразует, как правило, уже целевой код. Основными способами оптимизации на данном этапе могут быть различные эквивалентные замены последовательностей машинных команд на более быстрые аналоги, не меняющие поведения перестановки команд или блоков команд, приводящие к ускорению и т.п.
Большинство решений машинно-зависимой оптимизации принимаются на основе модели исполнительного устройства, встроенной в компилятор. Например, в компилятор может быть включена информация об относительном времени выполнения различных инструкций определённого процессора (или семейства процессоров).
эта немаловажная оговорка доставляет много боли начинающим, а иногда и опытным, разработчикам C и C++↩︎