
Linux pipes tips & tricks
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command_connect()’, когда встречает символ ‘|’.
parse.y:
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command_connect():make_cmd.c:
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute_connection():execute_cmd.c:
PIPE_IN и PIPE_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO_PIPE, которое означает, что I/O является stdin/stdout.
execute_pipeline() довольно объемная функция, имплементация которой содержится в execute_cmd.c. Мы рассмотрим наиболее интересные для нас части.
execute_cmd.c:
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
fs/pipe.c (пропущены незначительные для данной статьи участки кода):
Если вы обратили внимание, в коде идет проверка на флаг O_NONBLOCK. Его можно выставить используя операцию F_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
arch/arm/include/asm/limits.h:
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
Tips & trics
Перенаправление и stdout, и stderr в pipe
или же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
Перенаправление _только_ stderr в pipe
Shoot yourself in the foot
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null.
Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
И поместим ее в pipe:
Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
Shoot yourself in the foot
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:
Здесь мы печатаем все найденные строки, приписав ‘new_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Использование потоков, конвейеров и перенаправлений в Linux
Работаем в командной строке
Операционные системы Unix традиционно используют такие понятия, как стандартный ввод, вывод и вывод ошибки. Чаще всего ввод — это клавиатура, а вывод это на кран. Но конечно же мы можем выводить исполнение какой-то команды в файл и передавать другой команде, потому что работая в Linux, создается такая последовательность из команд, т.е результат предыдущей мы отправляем следующей и т.д
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Целью данной статьи является рассмотреть:
Стандартный вывод ошибок.
Следовательно, на экране мы уже не видим ошибки, потому что она отправилась в указанный файл.
Конвейер
Конвейер умеет передавать выходные данные из одной программы, как входные данные для другой. Т.е. выполняется команда, мы получаем результат и передаем эти данные далее на обработку другой программе.
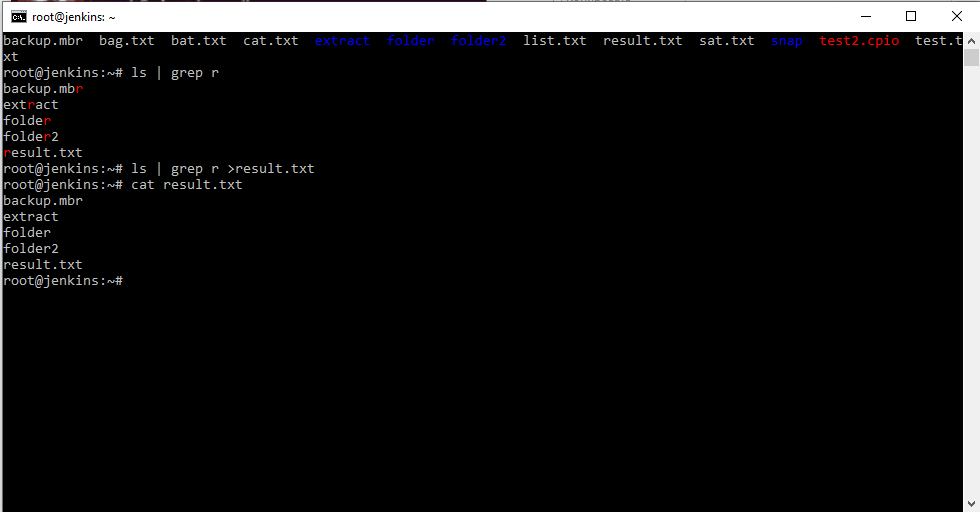
Как видите после данной конструкции команд файлов не осталось. Т.е. данные построчно передались на команду удаления, которая построчно каждый файл с ключом –f (принудительно) их и удалила.
Как реализованы конвейеры в Unix

О чём речь?
Конвейеры — «вероятно, самое важное изобретение в Unix» — это определяющая характеристика лежащей в основе Unix философии объединения воедино маленьких программ, а также знакомая надпись в командной строке:
Конвейеры обеспечивают однонаправленный канал межпроцессного взаимодействия. У конвейера есть вход (write end) и выход (read end). Данные, записанные во вход конвейера, могут быть считаны на выходе.
Результаты трассировки приведённой выше команды демонстрируют создание конвейера и поток данных через него из одного процесса в другой:
Без конвейеров оболочке пришлось бы записывать результат одного процесса в файл и передавать его другому процессу, чтобы тот прочитал данные из файла. В результате мы тратили бы больше ресурсов и место на диске. Однако конвейеры хороши не только тем, что позволяют избежать использования временных файлов:
Если процесс пытается прочитать из пустого конвейера, тогда read(2) заблокирует до тех пор, пока данные не станут доступны. Если процесс попытается записать в заполненный конвейер, тогда write(2) заблокирует до тех пор, пока из конвейера не будет считано достаточно данных для выполнения записи.
Как и POSIX-требование, это важное свойство: запись в конвейер вплоть до PIPE_BUF байтов (как минимум 512) должна быть атомарной, чтобы процессы могли взаимодействовать друг с другом через конвейер так, как обычные файлы (не предоставляющие таких гарантий) не могут.
При использовании обычного файла процесс может записать в него все свои выходные данные и передать другому процессу. Или процессы могут действовать в режиме жёсткого распараллеливания, с помощью внешнего сигнального механизма (вроде семафора) сообщая друг другу о завершении записи или чтения. Конвейеры избавляют нас от всех этих хлопот.
Что мы ищем?
Объясню на пальцах, чтобы вам было легче представить, как может работать конвейер. Вам понадобится выделить в памяти буфер и какое-то состояние. Понадобятся функции для добавления и удаления данных из буфера. Понадобится какое-то средство, чтобы вызывать функции в ходе операций чтения и записи в файловые дескрипторы. И понадобятся блокировки, чтобы реализовать описанное выше специальное поведение.
Теперь мы готовы допросить при ярком свете ламп исходный код ядра, чтобы подтвердить или опровергнуть нашу смутную мысленную модель. Но всегда будьте готовы к неожиданностям.
Где мы ищем?
Я не знаю, где лежит мой экземпляр известной книги «Lions book« с исходным кодом Unix 6, но благодаря The Unix Heritage Society можно в онлайне поискать в исходном коде ещё более старых версий Unix.
Блуждание по архивам TUHS сродни посещению музея. Мы можем взглянуть на нашу общую историю, и я испытываю уважение к многолетним усилиям по восстановлению всех этих материалов бит за битом со старых кассет и распечаток. И остро осознаю те фрагменты, которые ещё отсутствуют.
Удовлетворив своё любопытство в части древней истории конвейеров, для сравнения можем посмотреть на современные ядра.
Традиционные ядра Unix (1970–1974)
Я не нашёл никаких следов pipe(2) ни в PDP-7 Unix (январь 1970-го), ни в первой редакции Unix (ноябрь 1971-го), ни в неполном исходном коде второй редакции (июнь 1972-го).
TUHS утверждает, что третья редакция Unix (февраль 1973-го) стала первой версией с конвейерами:
Третья редакция Unix была последней версией с ядром, написанным на ассемблере, но при этом первой версией с конвейерами. В течение 1973-го велись работы по улучшению третьей редакции, ядро переписали на С, и так появилась четвёртая редакция Unix.
Один из читателей нашёл скан документа, в котором Даг МакИлрой предложил идею «соединения программ по принципу садового шланга».

В книге Брайана Кернигана «Unix: A History and a Memoir», в истории появления конвейеров тоже упоминается этот документ: «… он висел на стене в моём офисе в Bell Labs в течение 30 лет». Вот интервью с МакИлроем, и ещё одна история из работы МакИлроя, написанной в 2014-м:
Когда появилась Unix, моё увлечение корутинами заставило меня попросить автора ОС, Кена Томпсона, позволить данным, записанным в какой-то процесс, идти не только на устройство, но и на выход к другому процессу. Кен решил, что это возможно. Однако, как минималист, он хотел, чтобы каждая системная функция играла значительную роль. Действительно ли прямая запись между процессами имеет большое преимущество по сравнению с записью в промежуточный файл? И только когда я внёс конкретное предложение с броским названием «конвейер» и описанием синтаксиса взаимодействия процессов, Кен, наконец-то, воскликнул: «Я сделаю это!».
И сделал. Одним судьбоносным вечером Кен изменил ядро и оболочку, исправил несколько стандартных программ, стандартизировав их процедуру принятия входных данных (которые могут поступать из конвейера), а также поменял имена файлов. На следующий день конвейеры начали очень широко применять в приложениях. К концу недели секретарши с их помощью отправляли на принтер документы из текстовых редакторов. Чуть позднее Кен заменил оригинальный API и синтаксис для оболочки использования конвейеров на более чистые соглашения, которые с тех пор и применяются.
К сожалению, исходный код ядра третьей редакции Unix утерян. И хотя у нас есть написанный на С исходный код ядра четвёртой редакции, вышедшей в ноябре 1973-го, однако она вышла за несколько месяцев до официального релиза и не содержит реализации конвейеров. Жаль, что исходный код легендарной функции Unix утерян, возможно, навсегда.
У нас есть текст документации по pipe(2) из обоих релизов, поэтому можно начать с поиска в документации третьей редакции (по определённым словам, подчёркнутым «вручную», строка из литералов ^H, после которой идёт нижнее подчёркивание!). Этот прото- pipe(2) написан на ассемблере и возвращает только один файловый дескриптор, но уже предоставляет ожидаемую основную функциональность:
Системный вызов pipe создаёт механизм ввода вывода, который называется конвейером. Возвращаемый файловый дескриптор можно использовать для операций чтения и записи. Когда в конвейер что-то записывается, то буферизуется до 504 байтов данных, после чего процесс записи приостанавливается. При чтении из конвейера буферизированные данные забираются.
К следующему году ядро было переписано на С, а pipe(2) в четвёртой редакции обрёл свой современный облик с прототипом « pipe(fildes) »:
Системный вызов pipe создаёт механизм ввода вывода, который называется конвейером. Возвращаемые файловые дескрипторы можно использовать в операциях чтения и записи. Когда что-то записывается в конвейер, то используется дескриптор, возвращаемый в r1 (соотв. fildes[1]), то буферизуется до 4096 байтов данных, после чего процесс записи приостанавливается. При чтении из конвейера дескриптор, возвращаемый в r0 (соотв. fildes[0]), забирает данные.
Предполагается, что после определения конвейера два (или более) взаимодействующих процесса (созданных последующими вызовами fork) будут передавать данные из конвейера с помощью вызовов read и write.
В оболочке есть синтаксис для определения линейного массива процессов, соединённых посредством конвейера.
Вызовы на чтение из пустого конвейера (не содержащего буферизированных данных), имеющего лишь один конец (закрыты все записывающие файловые дескрипторы), возвращают «конец файла». Вызовы на запись в аналогичной ситуации игнорируются.
Самая ранняя сохранившаяся реализация конвейера относится к пятой редакции Unix (июнь 1974-го), но она почти идентична той, что появилась в следующем релизе. Лишь добавились комментарии, так что пятую редакцию можно пропустить.
Шестая редакция Unix (1975)
Начинаем читать исходный код Unix шестой редакции (май 1975-го). Во многом благодаря Lions найти его гораздо легче, чем исходники более ранних версий:
Многие годы книга Lions была единственным документом по ядру Unix, доступным вне стен Bell Labs. Хотя лицензия шестой редакции позволяла преподавателям использовать её исходный код, однако лицензия седьмой редакции исключила эту возможность, поэтому книга распространялась в виде нелегальных машинописных копий.
Сегодня можно купить репринтный экземпляр книги, на обложке которой изображены студенты у копировального аппарата. А благодаря Уоррену Туми (который запустил проект TUHS) вы можете скачать PDF-файл с исходным кодом шестой редакции. Хочу дать вам представление, сколько сил ушло на создание файла:
Больше 15 лет назад я набрал копию исходного кода, приведённого в Lions, потому что мне не нравилось качество моей копии с неизвестного количества других копий. TUHS ещё не существовало, и у меня не было доступа к старым исходникам. Но в 1988-м я нашёл старую ленту с 9 дорожками, на которой была резервная копия из компьютера PDP11. Трудно было понять, работает ли она, но там было неповреждённое дерево /usr/src/, в котором большинство файлов были помечены 1979-м годом, что уже тогда выглядело древностью. Это была седьмая редакция или её производная PWB, как я считал.
Я взял находку за основу и вручную отредактировал исходники до состояния шестой редакции. Часть кода осталась такой же, часть пришлось слегка подредактировать, поменяв современный токен += на устаревший =+. Что-то просто удалил, а что-то пришлось полностью переписать, но не слишком много.
И сегодня мы можем в онлайне читать на TUHS исходный код шестой редакции из архива, к которому приложил руку Деннис Ричи.
Кстати, на первый взгляд, главной особенностью С-кода до периода Кернигана и Ричи является его краткость. Не так часто мне удаётся вставлять фрагменты кода без обширного редактирования, чтобы он соответствовал относительно узкой области отображения на моём сайте.
В начале /usr/sys/ken/pipe.c есть поясняющий комментарий (и да, там есть ещё /usr/sys/dmr):
Размер буфера не менялся со времён четвёртой редакции. Но здесь мы безо всякой публичной документации видим, что когда-то конвейеры использовали файлы в качестве запасного хранилища!
Что касается LARG-файлов, то они соответствуют inode-флагу LARG, который используется «алгоритмом большой адресации» для обработки косвенных (indirect) блоков с целью поддержки более крупных файловых систем. Раз Кен сказал, что лучше их не использовать, то я с радостью поверю ему на слово.
Вот настоящий системный вызов pipe :
В комментарии ясно описано, что тут происходит. Но разобраться в коде не так просто, отчасти из-за того, как с помощью «struct user u» и регистров R0 и R1 передаются параметры системных вызовов и возвращаемые значения.
Попробуем с помощью ialloc() разместить на диске inode (индексный дескриптор), а с помощью falloc() — разместить в памяти два файла. Если всё пройдёт хорошо, то мы зададим флаги для определения этих файлов как двух концов конвейера, укажем их в том же inode (чей счётчик ссылок станет равен 2), и пометим inode как изменённый и использующийся. Обратите внимание на обращения к iput() в ошибочных путях (error paths) для уменьшения счётчика ссылок в новом inode.
Затем проверяем счётчик ссылок inode. Пока оба конца конвейера остаются открытыми, счётчик должен быть равен 2. Мы придерживаем одну ссылку (из rp->f_inode ), так что если счётчик будет меньше 2, то это должно означать, что читающий процесс закрыл свой конец конвейера. Иными словами, мы пытаемся писать в закрытый конвейер, а это является ошибкой. Впервые код ошибки EPIPE и сигнал SIGPIPE появились в шестой редакции Unix.
Но даже если конвейер открыт, он может быть заполнен. В этом случае мы снимаем блокировку и идём спать в надежде, что другой процесс прочитает из конвейера и освободит в нём достаточно места. Проснувшись, мы возвращаемся к началу, опять вешаем блокировку и запускаем новый цикл записи.
Теперь у нас есть всё, чтобы разобраться в функции readp() :
Возможно, вам будет проще читать эту функцию снизу вверх. Ветка «read and return» обычно используется, когда в конвейере есть какие-то данные. В этом случае мы с помощью readi() считываем столько данных, сколько доступно начиная с текущего f_offset чтения, а затем обновляем значение соответствующего смещения.
Комментарии к readi() и writei() помогут понять, что вместо передачи параметров через « u » мы можем обращаться с ними как с обычными функциями ввода-вывода, которые берут файл, позицию, буфер в памяти, и подсчитывают количество байтов для чтения или записи.
Что касается «консервативной» блокировки, то readp() и writep() блокируют inode до тех пор, пока не закончат работу или не получат результат (то есть вызовут wakeup ). plock() и prele() работают просто: с помощью другого набора вызовов sleep и wakeup позволяют нам пробуждать любой процесс, которому нужна блокировка, которую мы только что сняли:
На этом описание конвейеров в шестой редакции закончено. Простой код, далеко идущие последствия.
Седьмая редакция Unix (январь 1979-го) была новым основным релизом (спустя четыре года), в которой появилось много новых приложений и свойств ядра. Также в нём произошли значительные изменения в связи с использованием приведения типов, union’ов и типизированных указателей на структуры. Однако код конвейеров практически не изменился. Можем пропустить эту редакцию.
Xv6, простое Unix-образное ядро
На создание ядра Xv6 повлияла шестая редакция Unix, однако оно написано на современном С, чтобы его запускали на x86-процессорах. Код легко читать, он понятен. К тому же, в отличие от исходников Unix с TUHS, вы можете скомпилировать его, модифицировать и запустить на чём-то ещё кроме PDP 11/70. Поэтому это ядро широко используется в вузах как учебный материал по операционным системам. Исходники лежат на Github.
В коде содержится понятная и продуманная реализация pipe.c, подкреплённая буфером в памяти вместо inode на диске. Здесь я привожу только определение «структурного конвейера» и функции pipealloc() :
Linux 0.01
Современные ядра Linux, FreeBSD, NetBSD, OpenBSD
Я быстро пробежался по некоторым современным ядрам. Ни в одном из них уже нет реализации с использованием диска (не удивительно). В Linux своя собственная реализация. И хотя три современных BSD-ядра содержат реализации на основе кода, который был написан Джоном Дайсоном, за прошедшие годы они стали слишком сильно отличаться друг от друга.
Чтобы читать fs / pipe.c (на Linux) или sys / kern / sys_pipe.c (на *BSD), требуется настоящая самоотдача. Сегодня в коде важны производительность и поддержка таких функций, как векторные и асинхронные операции ввода-вывода. А подробности выделения памяти, блокировок и конфигурации ядра — всё это сильно разнится. Это не то, что нужно вузам для вводного курса по операционным системам.
В любом случае, мне было интересно раскопать несколько старинных паттернов (например, генерирование SIGPIPE и возврат EPIPE при записи в закрытый конвейер) во всех этих, таких разных, современных ядрах. Вероятно, я никогда не увижу вживую компьютер PDP-11, но ещё есть чему поучиться на коде, который был написан за несколько лет до моего рождения.
Написанная Диви Капуром в 2011-м году статья «The Linux Kernel Implementation of Pipes and FIFOs» представляет собой обзор, как работают (до сих пор) конвейеры в Linux. А недавний коммит в Linux иллюстрирует конвейерную модель взаимодействия, чьи возможности превышают возможности временных файлов; а также показывает, насколько далеко ушли конвейеры от «очень консервативной блокировки» в ядре Unix шестой редакции.
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
 После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
Стандартные потоки
Данное приложение все также эмулирует оконечное устройство, предназначенное для взаимодействия пользователя с компьютером. Точно также мы можем запустить сразу несколько терминалов, каждый из которых будет работать независимо. Кроме того, следует понимать, что терминал может быть запущен как локально, так и удаленно, способ подключения к компьютеру может быть разным, но свойства терминала от этого не изменяются.
Для взаимодействия запускаемых в терминале программ и пользователя используются стандартные потоки ввода-вывода, имеющие зарезервированный номер (дескриптор) зарезервированный на уровне операционной системы. Всего существует три стандартных потока:
Перенаправление потоков
Которая через стандартный поток ввода будет доставлена командному интерпретатору, тот запустит указанную программу и передаст ей требуемые аргументы, а результат вернет через стандартный поток вывода на устройство отображения информации.
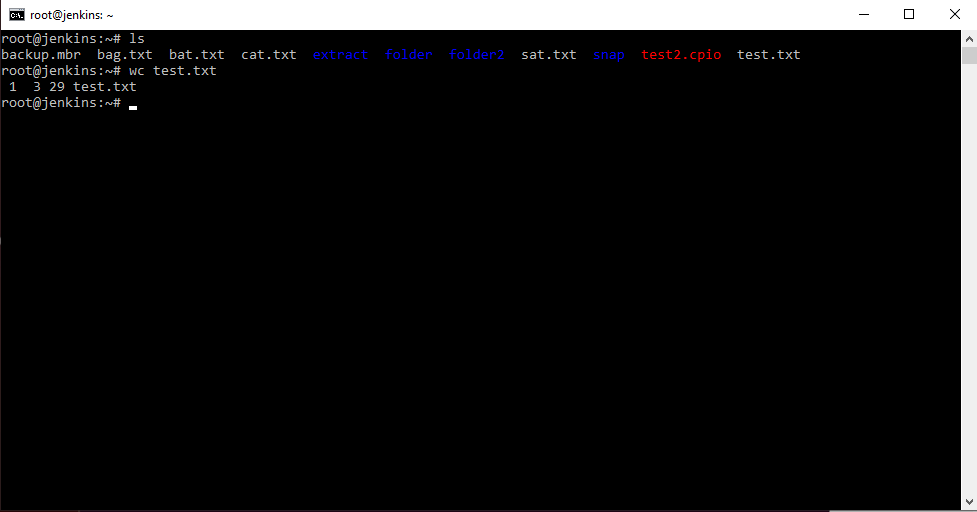
На экран теперь не будет выведено ничего, но весь вывод команды окажется в файле result, который мы можем прочитать следующим образом:

Немного изменим последовательность команд:
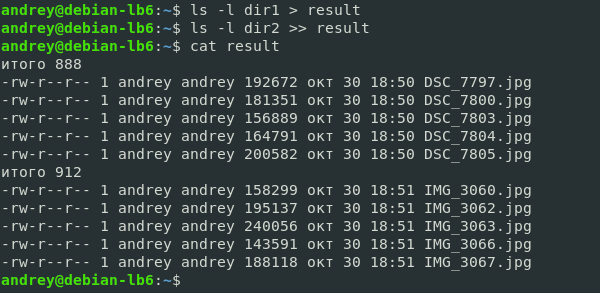
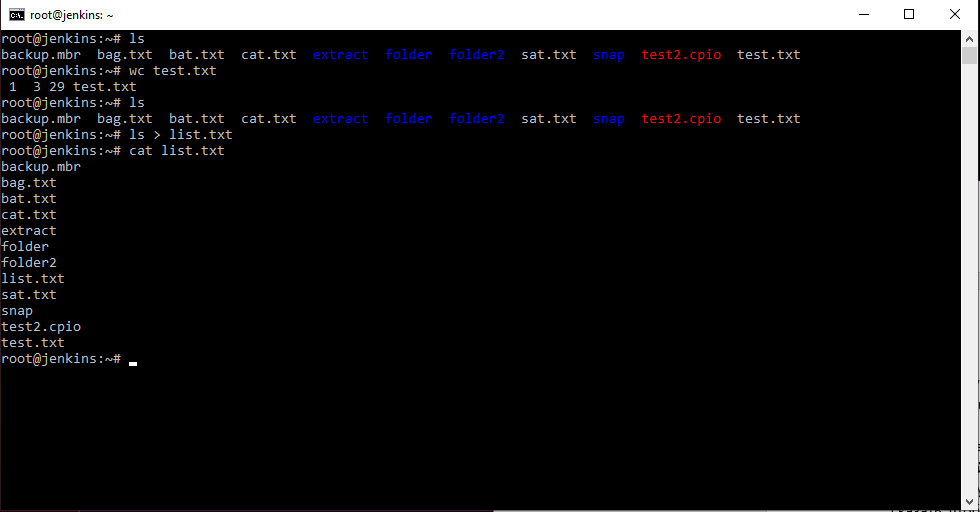
Теперь в файл попал вывод сразу двух команд, при этом, обратите внимание, первой командой мы перезаписали файл, а второй добавили в него содержимое из стандартного потока вывода.
Пойдем дальше. Как видим в выводе кроме списка файлов присутствуют строки «итого», нам они не нужны, и мы хотим от них избавиться. В этом нам поможет утилита grep, которая позволяет отфильтровать строки согласно некому выражению. Например, можно сделать так:
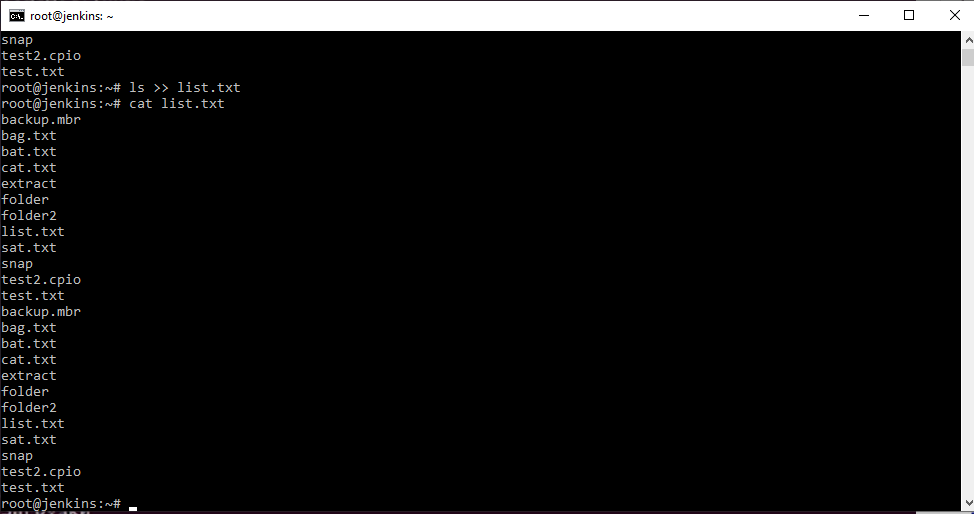
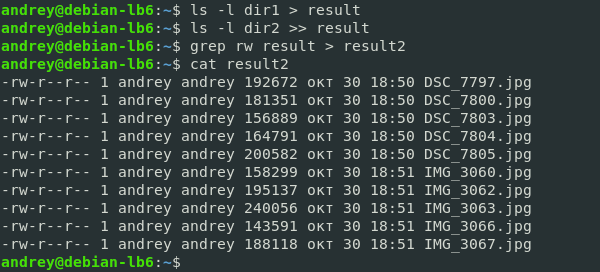 В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
Но это ничего не изменит, поэтому мы пойдем другим путем и перенаправим на ввод одной команды вывод другой:
На первый взгляд выглядит несколько сложно, но обратимся к man по grep:
В качестве паттерна мы используем rw, который есть в каждой интересующей нас строке, а в качестве файлов отдаем стандартный файл потока ввода, содержимого которого является результатом работы команды, указанной в скобках. А можно направить результат этой команды в файл? Конечно, можно:
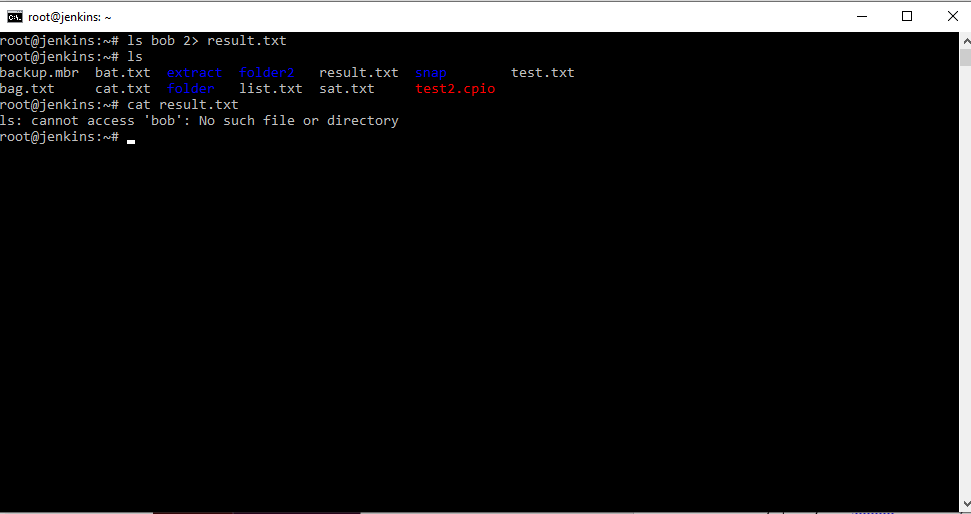
Немного особняком стоит стандартный поток вывода ошибок, допустим мы хотим получить список файлов несуществующей директории с перенаправлением вывода в файл, но сообщение об ошибке мы все равно получим на экран.
 Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
В данном примере весь вывод стандартного потока ошибок будет перенаправлен в пустое устройство /dev/null.
Но можно пойти и другим путем, перенаправив поток ошибок в стандартный поток вывода:
 В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
Конвейер
В предыдущих примерах мы научились перенаправлять стандартные потоки ввода-вывода и даже частично коснулись вопроса о направлении вывода одной команды на вход другой. А почему бы и нет? Потоки стандартные, это позволяет использовать вывод одной команды как ввод другой. Это еще один очень важный механизм, позволяющий раскрыть всю мощь Linux в реализации очень сложных сценариев достаточно простым способом.
Самый простой пример:
Первая команда выведет список всех установленных пакетов, вторая отфильтрует только те, в наименовании которых есть строка «gnome».
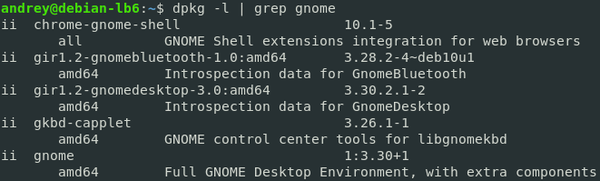 Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
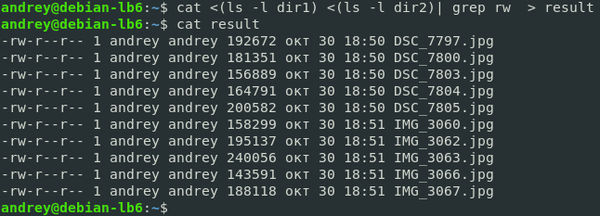 Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Еще один важный момент, если вы повышаете права с помощью команды sudo, то данное повышение прав через конвейер не распространяется. Например, если мы решим выполнить:
То первая команда будет выполнена с правами суперпользователя, а вторая с правами запустившего терминал пользователя.
Дополнительные материалы:
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:

Или подпишись на наш Телеграм-канал: 